Claude 3 sonnet vs GPT 4: What is the best LLM for your App?
Exciting news, phospho is now bringing brains to robots!
With phosphobot, you can control robots, collect data, fine-tune robotics AI models, and deploy them in real-time.
Check it out here: robots.phospho.ai.
Choosing the right LLM to integrate is an important decision as it lays the foundation and scope for AI capabilities within your app. Anthropic’s flagship LLM Claude has been challenging OpenAI’s GPT-4 top spot for the leading LLM in the market.
Seeing where Claude 3 Sonnet and GPT-4 thrive in certain use cases will help us answer the question of this article - which one is right for your LLM app? We will also touch on how we can use LLM text analytics platforms like Phospho to help monitor, learn and evaluate the performance of LLMs in our apps.
Following this series of LLM comparison and use cases presentation, you can find here 1 additional article in which we're showing you how to best use Claude 3 Opus Context Window: Read me
We've also built a free guide on how to build AI SaaS in 2024 with a data-driven approach. You can get access: Here
If you want to learn how to build actionable AI dashboards you can also check this free guide: Here.
Quick TLDR Comparison summary
This comparison will not look like much of a competition based on just the numbers because for most of the (standardized) benchmark performance tests, Claude 3 either matches or surpasses GPT-4 in performance:
- Claude 3 > GPT-4 for understanding and processing images, videos, and charts.
- Claude 3 > GPT-4 for communication in non-English languages like Spanish, Japanese, and French.
- Claude 3 > GPT-4 for remembering context. Claude: 200K tokens, GPT-4: 128K tokens.
- GPT-4 > Claude 3 in terms of the number of plugins, which makes it a better choice for AI startups that need flexibility.
Understanding Claude 3 Sonnet
For a little context, Claude 3 is an AI model released by Anthropic who like to position themselves as a responsible AI firm and they’re approach to development includes 3 things:
- Safety and alignment of AI
- Transparency into the limits and capabilities of their model
- Commitment to responsible AI deployment
It’s currently popular opinion that Claude 3 can understand the nuance of human communication better than other LLMs, making it a favorite amongst many generative AI users—both casual and serious.
Claude 3’s large context window makes it very good at most things. In the tasks for the benchmark tests it remembered over 99% of the time in tough tests, showing its strong memory. It can even handle complex academic tasks with ease but it really stands out for coding and scores a high 92% on HumanEval which is better than GPT-4.
Claude 3 Sonnet is fast and it’s not too pricy. In fact, it's twice as fast as Claude 3 Opus but cheaper, making it good for big AI uses. It has a big 200K token window and is priced well, offering great value for businesses and developers.
Claude 3 Sonnet is also good at understanding many languages and cultures. It can translate tricky expressions and keep the original meaning, and it can do so ethically, making it useful in many people-related fields.
With its great performance, speed, and value, Claude 3 Sonnet would particularly excel at support bots, detailed data analysis, and coding.
Based on the benchmark scores shared by Anthropic on its official website (image attached to this article) the company claims this marks a big leap by outperforming current standard in other LLMs in the market.
Understanding GPT-4
GPT-4 is a large language model developed by OpenAI. They have an ethos of pushing the boundaries with AI capabilities, and their approach to AI development is understandably one of innovation:
- iterative improvement through scale up models
- broad accessibility through API and partnerships
- exploration of AI’s potential across diverse applications
GPT-4 can handle a lot of text, up to 128,000 characters, for better conversations. But Claude AI can do even more, with up to 200,000 characters, for longer conversations with users.
GPT-4 does more than just text. It can make images and get the latest info from the web. In regards to use cases, this makes GPT-4 a really good choice for creative content creation, interactive storytelling, and projects that need the latest facts.
Developers will like GPT-4's coding skills. It can make Python code for tasks like finding a circle's area, just like other top models. But, it might add things you don't need in its code.
Additionally, despite falling short to Claude 3, GPT-4 has outstanding multimodal capabilities, able to process inputs combining images and text, and has made significant advancements in visual understanding.
While GPT-4 is great in many ways, think about what you really need for your app. Consider things like coding needs, how you want to talk, and how easy it is to add to your app. It is however more flexible when it comes to integrations.
Comparison Metrics: Claude 3 Sonnet vs GPT-4
As we’ve touched on, Claude 3 fared much better than GPT-4 in tasks that clearly required advanced reasoning and coding abilities, thus, it should be more appropriate for applications requiring heavy cognitive processing.
Claude 3 demonstrates an almost unbelievable super-long memory, capable of processing up to 200K tokens of context window at once, equivalent to reading 500 pages of a book in a few seconds, thus having a significant advantage in handling super-long texts and codebases. In comparison, although the latest version of GPT-4, GPT-4 Turbo, has a context processing capability of 128K tokens, sufficient for most daily needs, there is still a noticeable gap compared to Claude 3.
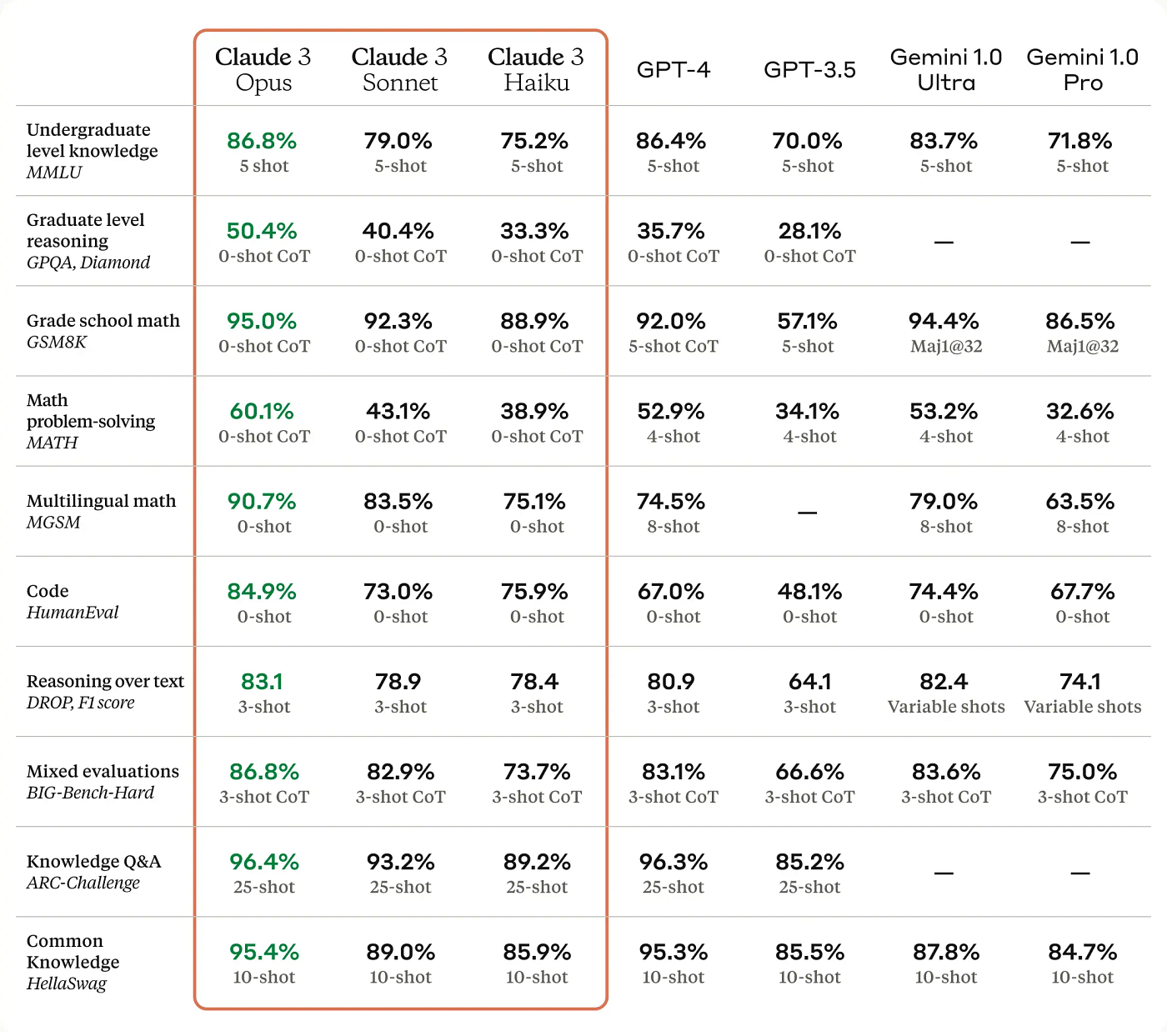
Here are the individual comparisons from the image at the top of this article in bullet points:
- Undergraduate Level Knowledge: Claude 3 Opus scores 86.8%, slightly ahead of GPT-4’s 86.4%
- Graduate Level Reasoning: Claude 3 Opus has a significant lead on this one with 50.4%, compared to GPT-4’s 35.7%
- Grade School Maths: Claude 3 Opus achieves 95.0%, slightly surpassing GPT-4’s 92.0%
- Multilingual Maths: Claude 3 Opus leads significantly with 90.7%, compared to GPT-4’s 74.5%
- Coding (HumanEval): Claude 3 Opus scores 84.9%, notably higher than GPT-4’s 67.0%
- Reasoning Over Text: Claude 3 Opus at 83.1% is only slightly ahead of GPT-4’s 80.9%
- Mixed Evaluations: Claude 3 Opus outperforms again with 86.8%, in contrast to GPT-4’s 83.1%
- Knowledge Q&A: Claude 3 Opus marginally leads with 96.4% while GPT-4 is close behind at 96.3%
- Common Knowledge: Claude 3 Opus scores 95.4%, better than GPT-4’s 95.3% by a fraction
The overall results indicate that while GPT-4 is a highly competent model, Claude 3 Opus shows better capabilities in dealing with a variety of problem-solving and knowledge based tasks, possibly making it a more potent tool for tackling slightly more sophisticated AI challenges.
Choosing the Right LLM for Your App: A 3-Step Plan
Step 1: Define your needs
Basically, think about how complex tasks are, how fast you need answers, and your budget. Knowing what your app really needs is a good first step.
For quick answers, with Claude 3 being better at retaining and understanding context, this would be good for use cases involving human communication and the need for more accuracy.
However, GPT-4’s faster speed and time to first token (TTFT) make it a superior choice for voice AI startups with critical latency. For startups with more flexible and varying LLM needs GPT-4 also offers easier integrations and a wide range of plugin options which might make it easier if pivoting is ever a consideration.
Step 2: Evaluate metrics and perform tests
This is where it’s crucial to qualitatively measure the performance of your chosen model in your LLM app.
So, after setting your needs for your LLM app, run small tests to check important metrics, such as how accurate, fast, or efficient the chosen model is for your app's specific tasks.
For that, you can use tools like Phospho to see how well your chosen LLM performs in your app by monitoring and evaluating real time performance and gathering feedback from your text analytics.
Step 3: Make an informed decision
After testing comes important decision-making. Take into account things like what's really important for your application in the long run, such as the amount of context an LLM app needs to function well. Remember, GPT-4 can handle 128K tokens, and Claude 3 will go as high as 200K tokens.
Also, think about costs. This is measured in dollars per million tokens. A hundred tokens are approximately the equivalent of 65 words. Claude 3 sonnet will cost $6/million tokens, whereas GPT-4 will cost $7.5/million at the time of writing this article.
One way to tackle the costs of using big LLMs such as Claude 3 or GPT-4 would be to experiment with optimization techniques like prompt engineering, which can be time-consuming, or simply use text analytics with tools like Phospho to fine-tune lower-cost models to improve output quality for your specific use case. It’s a trade-off, but this might achieve comparable performance to more expensive options like the big two but at a lower cost.
Conclusion - which is better?
Ultimately, the best choice will depend on your specific needs and use cases. For LLM apps that demand more factual accuracy, complex coding, and slightly tighter budgets, Claude might be a better fit.
On the other hand, GPT-4 is much better for avid API users and those leaning toward extensive AI functionalities. This is because Chat GPT integrates really easily. However, if you also need a wider range of functions or capabilities and are willing to pay, ChatGPT has a lot of plugins to choose from, which could make things easier for you.
It will always be hard to choose between two great models, but one thing is for sure: As AI technology and LLMs continue to improve, we’ll all be using them. The choice will depend on your LLM application and your long-term vision. We hope this article gave you more insight into making a more informed choice.
Want to take AI to the next level?
At Phospho, we give brains to robots. We let you power any robot with advanced AI – control, collect data, fine-tune, and deploy seamlessly.
New to robotics? Start with our dev kit.
👉 Explore at robots.phospho.ai.