Decoding SmolVLA: A Vision-Language-Action Model for Efficient and Accessible Robotics

In the rapidly advancing domain of robotic intelligence, Vision-Language-Action (VLA) models have emerged as crucial frameworks, empowering robots to interpret and perform tasks described using natural language. Despite their impressive capabilities, existing VLA models often require extensive computational resources, significantly restricting their accessibility and adoption in real-world applications.
Addressing this limitation, SmolVLA has been introduced, delivering efficiency without compromising performance. This blog post provides an in-depth exploration of SmolVLA’s architecture, training methodologies, inference mechanisms, comprehensive experimental evaluations and detailed ablation studies.
SmolVLA Architecture: Compact and Efficient
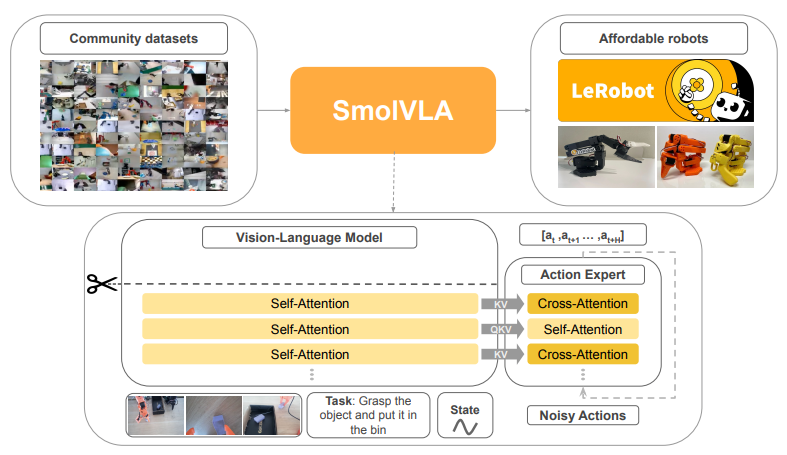
SmolVLA balances computational efficiency with robust functionality, making it ideal for deployment on widely accessible, consumer-grade hardware. It primarily comprises two tightly integrated components:
- Vision-Language Model (VLM): A streamlined, pre-trained model specialized in extracting rich multimodal feature representations.
- Action Expert: A transformer-based module, meticulously trained through Flow Matching techniques, to translate the VLM-encoded features into precise sequences of robotic actions.
A core innovation within SmolVLA is its strategic reduction of computational overhead achieved through "layer skipping", wherein upper layers of the VLM are selectively omitted. This careful omission preserves crucial feature representation capabilities while enhancing inference speed and efficiency.
Advanced Feature Extraction Techniques
SmolVLA utilizes SmolVLM-2, an optimized, compact VLM specifically designed for efficient multimodal data processing. The model leverages pixel-shuffling techniques to minimize the visual token count significantly, restricting each frame to 64 tokens. This optimized process reduces computational demands dramatically, enabling rapid inference without compromising representational quality.
Enhanced Attention Mechanisms
Traditional VLAs rely heavily on either self-attention (SA) or cross-attention (CA). SmolVLA innovatively employs an interleaved combination of CA and causal SA:
- Cross-Attention (CA): Allows direct conditioning of the action expert on VLM-derived features, providing robust contextual grounding.
- Causal Self-Attention (SA): Ensures coherent action sequences by imposing causal constraints, thus maintaining temporal consistency and enhancing predictive smoothness.
The strategic combination of CA and SA within SmolVLA significantly improves real-world deployment effectiveness.
Leveraging Community-Generated Data
SmolVLA’s training strategy capitalizes on publicly available, community-generated datasets characterized by considerable variability, reflecting diverse robotic platforms, heterogeneous environments, and real-world conditions with inherent noise and variability.
To overcome annotation inconsistencies prevalent in community datasets, SmolVLA leverages the pre-trained VLM Qwen2.5-VL-3B-Instruct to auto-generate standardized task descriptions. This automated approach enhances the dataset quality, enabling more effective and scalable training.
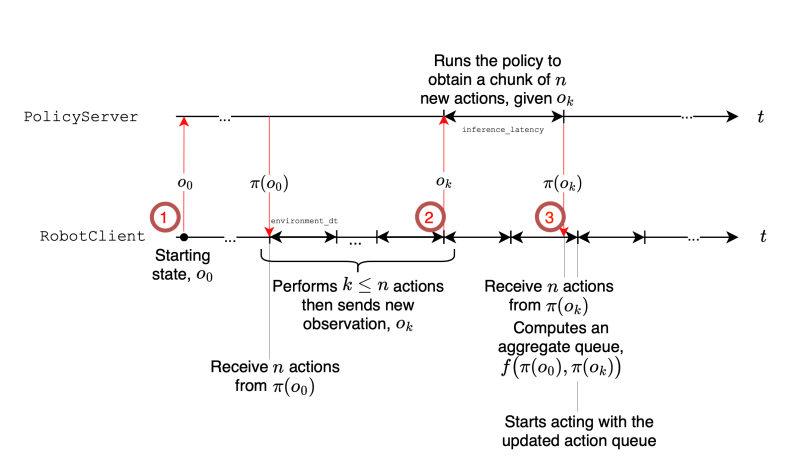
Asynchronous Inference Mechanism
SmolVLA introduces a pioneering asynchronous inference mechanism, effectively addressing the responsiveness challenges typical in robotics by clearly separating action prediction from execution:
- RobotClient: Continuously executes actions maintained in a local queue, ensuring consistent responsiveness.
- PolicyServer: Asynchronously processes observations from the RobotClient, predicting subsequent actions without interrupting the robot’s ongoing activities.
This approach reduces idle times, allowing the computational load to be offloaded onto powerful, remote servers. Consequently, robots operating in resource-limited environments experience enhanced efficiency and adaptability.
Measurable Performance Improvements
Extensive real-world testing validates asynchronous inference advantages:
- Notably quicker task completion rates, achieving up to 30% faster outcomes.
- Increased task throughput, with higher task cycles completed within constrained evaluation windows.

Experimental Validation
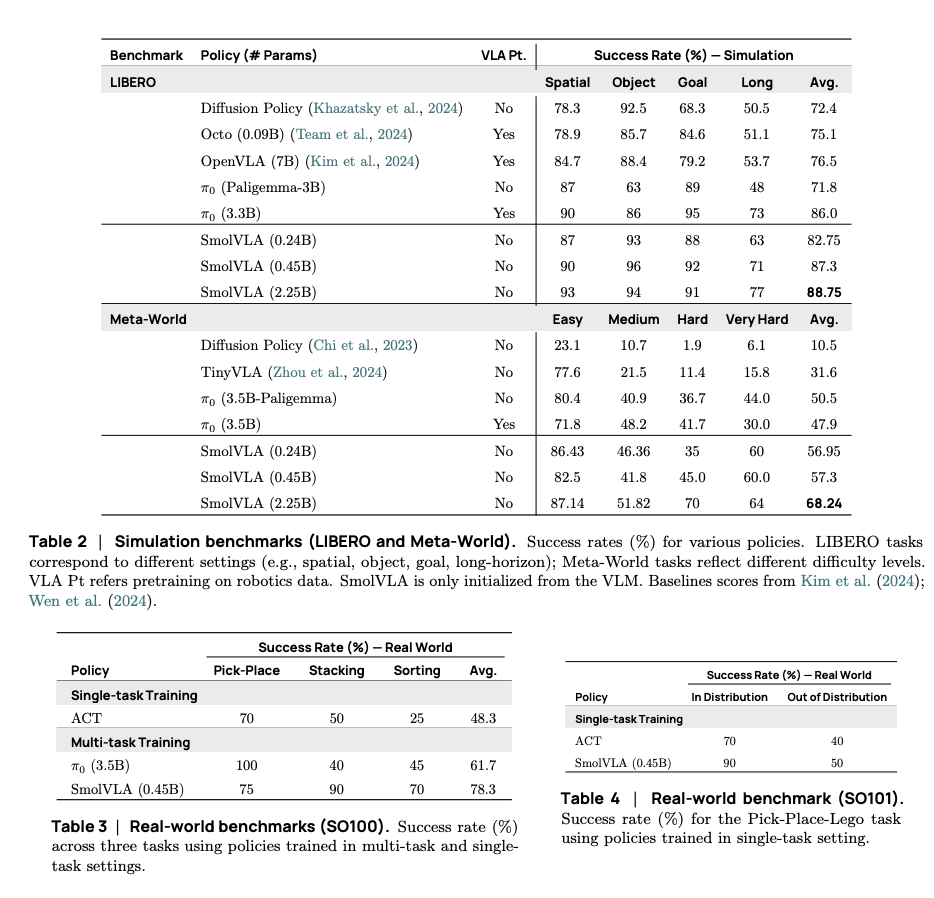
SmolVLA has undergone comprehensive evaluations in both simulated environments and practical, real-world robotics scenarios:
- Simulated Benchmarks: Evaluated on benchmarks like Meta-World and LIBERO, SmolVLA outperformed established baselines (π0, OpenVLA), demonstrating superior performance despite utilizing fewer resources and parameters.
- Real-World Scenarios: Achieved high success rates across challenging tasks, including pick-and-place, stacking, and sorting, demonstrating robust generalization capabilities even when tested against novel robotic platforms and untrained scenarios.

Detailed Ablation Studies
Comprehensive ablation studies systematically explored various components and design decisions within SmolVLA, uncovering crucial factors influencing performance:
- Attention Mechanisms: Confirmed the superiority of interleaved CA and SA, offering the optimal balance between feature contextualization and temporal coherence.
- Layer Skipping Efficacy: Demonstrated that using essential early layers from the VLM provided an ideal trade-off, significantly cutting computational demands while maintaining high-quality performance.
- Action Expert Capacity Tuning: Revealed that meticulously adjusting the expert’s hidden dimensions directly influenced efficiency-performance trade-offs.
- Flow Matching vs. Regression Objectives: Clearly established the superior efficacy of the Flow Matching objective over standard regression methods, particularly in handling complex, multimodal action distributions.
Future Directions and Limitations
While SmolVLA advances the field, several critical areas remain open for further exploration:
- Enhanced Dataset Diversity: Expanding training data to include diverse robot embodiments can substantially enhance generalization.
- Increased Dataset Scale: Larger datasets can further reinforce SmolVLA’s robustness and task generalization capabilities.
- Model Scaling Strategies: Investigating scalable model architectures without incurring excessive computational overhead remains a crucial area.
- Specialized VLM Backbones: Developing or identifying dedicated VLM backbones tailored explicitly for robotic tasks could significantly boost performance.
- Reinforcement Learning Integration: Integrating reinforcement learning approaches alongside imitation learning can enhance performance in complex, long-horizon tasks.
Using phospho: Fine-Tuning and Inference Made Simple
Instead of wrestling with local compute, phosphobot offers a streamlined solution using its cloud GPU infrastructure. Built for ML engineers, phosphobot integrates with the SO-100 robot arm (and others) and supports most robotics AI models out of the box. Here’s why it’s the best way to train and test your own model:
- One-Click Fine-Tuning: From the phosphobot dashboard, you can fine-tune robotics AI models on your own dataset (e.g., recorded via teleoperation with the Meta Quest app). Just upload your LeRobot v2.1 dataset to Hugging Face, enter its ID (e.g., phospho-app/my-dataset), and hit “Train AI Model.” Phosphobot’s cloud handles the heavy lifting—think A100 or H100 GPUs—taking ~3 hours for ~50 episodes. No need to wrangle local GPUs or debug CUDA errors.
- Seamless Inference: Once trained, your model (e.g., phospho-app/my-dataset-random-id) is ready for inference. In the dashboard’s “AI Training and Control” section, enter your model ID, specify a task instruction (e.g., “pick up the green lego brick”), and click “Start AI Control.” Phosphobot spins up a cloud GPU instance, streams camera feeds, and sends actions to your robot in real time. You can pause, resume, or tweak instructions on the fly.
- LeRobot Compatibility: Phosphobot uses the LeRobot dataset format, ensuring your data works with most robotics AI models. Record datasets via teleoperation, repair/merge/split them in the dashboard, and visualize them with Hugging Face’s LeRobot Dataset Visualizer.
- Hardware Simplicity: All you need is a computer to run the phosphobot server (phosphobot run) and an SO-100 arm with cameras. The cloud handles compute, so your laptop or Raspberry Pi is enough to orchestrate control.
To get started, install phosphobot on Mac, Linux or Windows with a single command:
# macos
curl -fsSL https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.sh | bash
# linux
curl -fsSL https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.sh | sudo bash
# windows
powershell -ExecutionPolicy ByPass -Command "irm https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.ps1 | iex"
Learn more about phospho and how to get started in the documentation.
Conclusion and Broader Impacts
SmolVLA contributes to robotics by making vision-language-action capabilities accessible through efficient computational methods, asynchronous inference, and the use of community-driven datasets.
The open-source release of SmolVLA—including models, code, and datasets—supports collaboration within the robotics community, potentially facilitating further advancements in robotic intelligence.