Dissecting Action Chunking with Transformers (ACT): Precision Imitation Learning for Robotic Manipulation
Fine-grained robotic manipulation tasks, such as threading a zip tie or opening a translucent condiment cup, demand high precision, delicate coordination, and robust visual feedback. These tasks challenge traditional imitation learning due to compounding errors, non-Markovian human behavior, and noisy demonstration data. Action Chunking with Transformers (ACT) is a novel algorithm designed to address these issues, enabling robots to learn complex bimanual manipulation with 80-90% success rates from just 10 minutes of human demonstrations.
This blog post dives into the technical details of ACT, exploring its design, implementation, and performance, as part of a series on robotics AI models.
The Challenge of Imitation Learning for Fine Manipulation
Imitation learning, particularly behavioral cloning (BC), trains a policy to map observations to actions using expert demonstrations. For high-precision tasks requiring closed-loop visual feedback and high-frequency control (50Hz), BC struggles with three key issues:
- Compounding Errors: Small errors in predicted actions accumulate over time, pushing the robot into states outside the training distribution, leading to task failure. For example, a millimeter-level error in grasping a velcro tie can derail subsequent insertion steps.
- Non-Markovian Behavior: Human demonstrations often include pauses or temporally correlated actions (e.g., waiting before prying open a lid), which single-step Markovian policies cannot model effectively.
- Noisy Human Data: Human trajectories vary even for the same task, requiring the policy to prioritize high-precision regions (e.g., grasping a battery) while handling stochasticity in less critical areas (e.g., approach paths).
ACT tackles these challenges with a combination of action chunking, temporal ensembling, and a conditional variational autoencoder (CVAE) framework, enabling robust learning from limited, noisy human demonstrations.
ACT’s Core Innovations
ACT introduces a novel approach to imitation learning by predicting sequences of actions and leveraging transformer-based sequence modeling. Its key components are action chunking, temporal ensembling, and a CVAE-based policy.
Action Chunking
Drawing inspiration from neuroscience, where actions are grouped into chunks for efficient execution, ACT predicts a sequence of ( k ) actions (target joint positions for the next ( k ) timesteps) given the current observation, rather than a single action. This reduces the effective task horizon by a factor of ( k ), mitigating compounding errors. For a task with 500 timesteps at 50Hz (10 seconds), setting ( k=100 ) reduces the horizon to 5 steps, making it easier for the policy to stay on track.
Action chunking also addresses non-Markovian behavior. Human demonstrations often include pauses or correlated actions (e.g., nudging a cup before grasping it), which single-step policies struggle to model. By predicting ( \pi_\theta(a_{t:t+k} | s_t) ), where ( s_t ) includes four RGB images (480x640) and 14 joint positions (7 per arm for a bimanual setup), and ( a_t ) is a 14-dimensional vector of target joint positions, ACT captures temporal dependencies within each chunk. This allows the policy to model complex behaviors like waiting or sequential coordination without requiring explicit history conditioning.
Temporal Ensembling
A naive implementation of action chunking can lead to jerky robot motion, as new observations are incorporated only every ( k ) steps. To ensure smooth execution, ACT queries the policy at every timestep, producing overlapping action chunks. At timestep ( t ), multiple predictions for ( a_t ) (from chunks starting at ( t-k+1, \ldots, t )) are combined using a weighted average with exponential weights ( w_i = \exp(-m \cdot i) ), where ( m ) controls the rate of incorporating new observations.
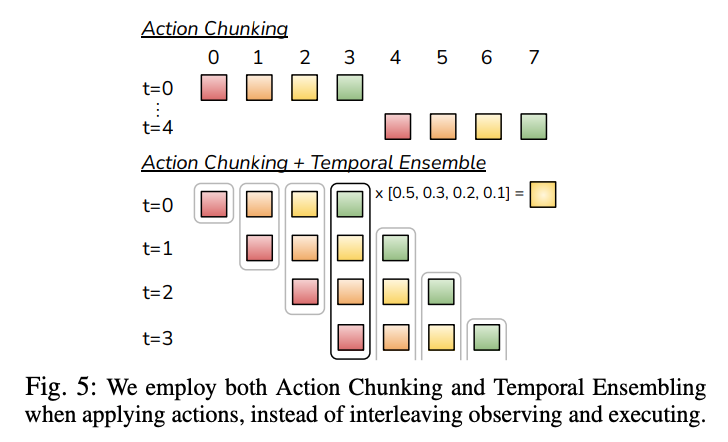
This temporal ensembling reduces modeling errors without introducing bias, unlike traditional smoothing over adjacent timesteps, and incurs only minimal inference-time computation overhead.
Modeling Noisy Data with a Conditional VAE
Human demonstrations are inherently stochastic, with variations in trajectories for the same task. For example, in a tape handover task, the exact mid-air handover position varies across episodes, but the policy must ensure the grippers avoid collisions and grasp correctly. To handle this, ACT trains the policy as a Conditional Variational Autoencoder (CVAE), which models the distribution of action sequences conditioned on observations.
The CVAE consists of:
- Encoder: Compresses an action sequence ( a_{t:t+k} ) and proprioceptive observations (joint positions) into a latent style variable ( z ), parameterized as a diagonal Gaussian. The encoder is used only during training and discarded at test time.
- Decoder (Policy): Predicts the action sequence ( a_{t:t+k} ) given the current observation (four RGB images and joint positions) and ( z ). At test time, ( z ) is set to zero (the mean of the prior), ensuring deterministic outputs for consistent policy evaluation.
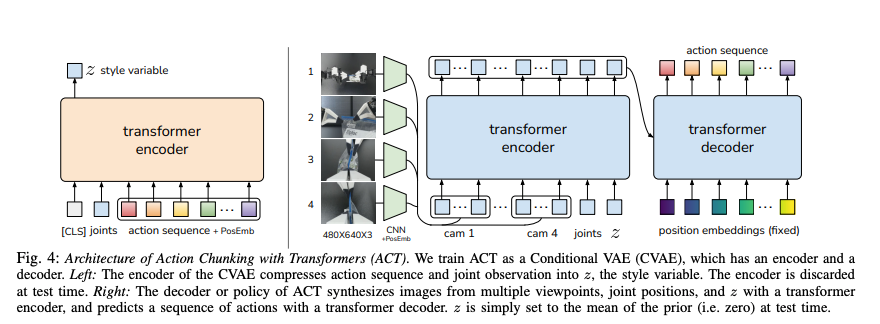
The CVAE is trained to maximize the log-likelihood of demonstration action chunks, using an L1 reconstruction loss for precise action modeling and a KL-divergence term weighted by a hyperparameter ( \beta ) to regularize the encoder. This allows ACT to focus on high-precision regions (e.g., grasping a battery) while capturing variability in less critical areas, improving robustness to noisy human data.
Implementation Details
ACT leverages transformers for sequence modeling, making it well-suited for predicting action chunks. The architecture includes:
- CVAE Encoder: A BERT-like transformer processes a sequence of length ( k+2 ), consisting of a learned [CLS] token, embedded joint positions, and the action sequence. The [CLS] token’s output is passed through a linear layer to predict the mean and variance of ( z ).
CVAE Decoder (Policy): A transformer encoder synthesizes features from four ResNet18-processed RGB images, joint positions, and ( z ). Each image (480x640x3) is converted to a 15x20x512 feature map, flattened into a 300x512 sequence, and augmented with 2D sinusoidal position embeddings to preserve spatial information. The resulting 1200x512 sequence (from four cameras) is concatenated with projected joint positions and ( z ), both mapped to 512 dimensions. A transformer decoder generates the action sequence (a ( k \times 14 ) tensor) via cross-attention, with fixed sinusoidal embeddings as queries.
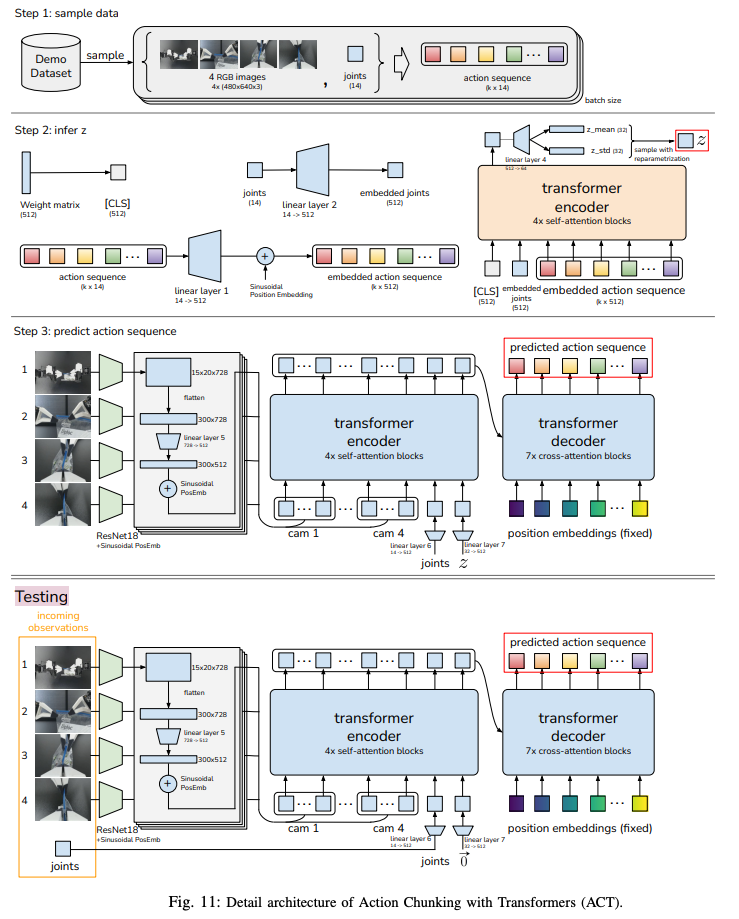
The model has approximately 80 million parameters, trains in 5 hours on a single RTX 2080 Ti GPU, and infers in 0.01 seconds. Key hyperparameters include a chunk size ( k=100 ), ( \beta=10 ), and a dropout rate of 0.1.
The use of L1 loss over L2 loss ensures precise action modeling, and absolute joint positions (rather than deltas) improve performance for fine manipulation.
Experimental Evaluation
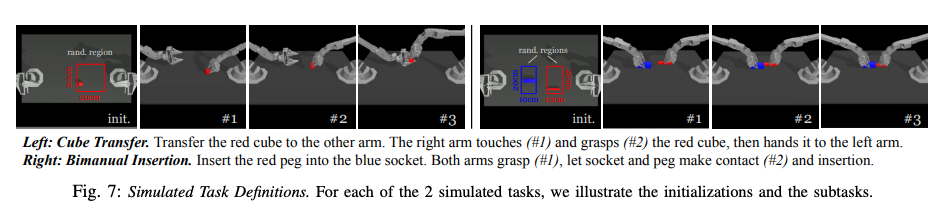
ACT was evaluated on eight bimanual manipulation tasks: six real-world tasks using a low-cost teleoperation system and two simulated tasks in MuJoCo

These tasks involve transparent or low-contrast objects (e.g., ziploc bags, condiment cups), posing significant perception challenges.
Tasks and Data Collection
Real-world tasks include:
- Slide Ziploc: Grasping and opening a ziploc bag’s slider.
- Slot Battery: Inserting a battery into a remote controller.
- Open Cup: Tipping and opening a translucent condiment cup.
- Thread Velcro: Inserting a velcro tie into a 3mm loop.
- Prep Tape: Cutting and hanging tape on a box.
- Put On Shoe: Fitting and securing a shoe on a mannequin foot.
Simulated tasks are Cube Transfer (handing a cube between arms) and Bimanual Insertion (inserting a peg into a socket). Each real-world task uses 50-100 demonstrations, each 8-14 seconds (400-700 timesteps at 50Hz), totaling 10-20 minutes of data. Simulated tasks use both scripted and human demonstrations, with 50 episodes each. Demonstrations are collected using a teleoperation system, recording leader robot joint positions as actions and four camera feeds plus follower joint positions as observations.

Performance
ACT achieves 80-96% success rates on most real-world tasks, significantly outperforming baselines like BC-ConvMLP, BeT, RT-1, and VINN

For example, ACT reaches 88% on Slide Ziploc and 96% on Slot Battery, while baselines fail to progress beyond initial subtasks (e.g., grasping). On simulated tasks, ACT outperforms baselines by 20-59%, with human data proving more challenging due to stochasticity.
The Thread Velcro task, with a 20% success rate, highlights perception limitations, as the black velcro tie blends with the background, and small errors in mid-air grasping compound during insertion. Ablation studies demonstrate the importance of:
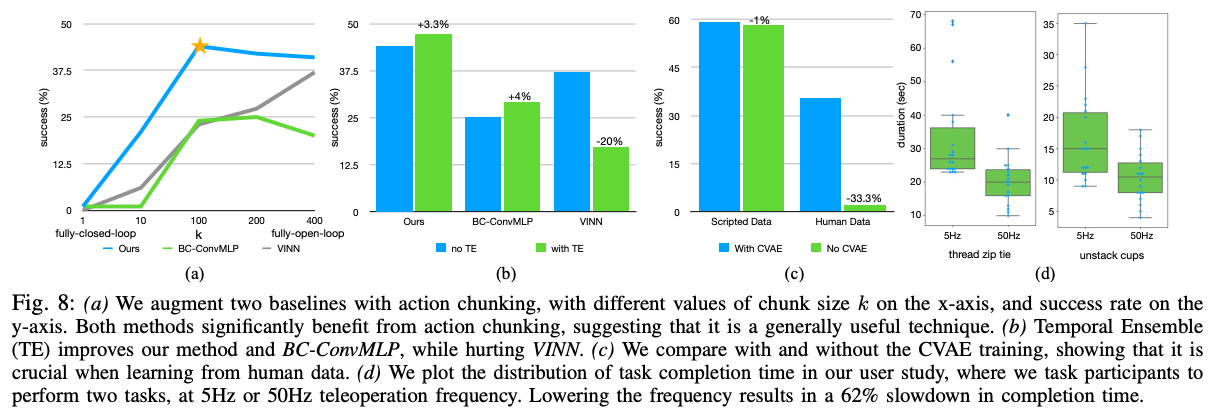
- Action Chunking: Success rates improve from 1% at ( k=1 ) (no chunking) to 44% at ( k=100 ), with a slight drop at higher ( k ) due to reduced reactivity
- Temporal Ensembling: Adds a 3.3% performance gain for ACT by smoothing predictions, though it may not benefit non-parametric methods like VINN
- CVAE Objective: Critical for human data, with performance dropping from 35.3% to 2% without CVAE, while scripted data shows no difference due to its determinism
High-Frequency Control
A user study with six participants underscores the need for high-frequency (50Hz) control. At 5Hz, tasks like threading a zip tie take 62% longer (33s vs. 20s), confirming that low-frequency control hinders precision in fine manipulation.
Limitations and Future Directions
ACT struggles with tasks like unwrapping candies or opening flat ziploc bags, where perception is challenging due to ambiguous visual cues (e.g., candy wrapper seams) or deformable objects. In preliminary tests, ACT failed to unwrap candies (0/10 success) despite picking them up consistently, due to difficulty localizing the seam. Similarly, opening a flat ziploc bag was hindered by variable deformations affecting the pulling region. Increasing demonstration data, improving perception models, or incorporating pretraining could address these issues.
Using phospho: Fine-Tuning and Inference Made Simple
Instead of wrestling with local compute, phosphobot offers a streamlined solution using its cloud GPU infrastructure. Built for ML engineers, phosphobot integrates with the SO-100 robot arm (and others) and supports ACT out of the box. Here’s why it’s the best way to try ACT:
- One-Click Fine-Tuning: From the phosphobot dashboard, you can fine-tune ACT on your own dataset (e.g., recorded via teleoperation with the Meta Quest app). Just upload your LeRobot v2.1 dataset to Hugging Face, enter its ID (e.g., phospho-app/my-dataset), and hit “Train AI Model.” Phosphobot’s cloud handles the heavy lifting—think A100 or H100 GPUs—taking ~3 hours for ~50 episodes. No need to wrangle local GPUs or debug CUDA errors.
- Seamless Inference: Once trained, your model (e.g., phospho-app/my-dataset-random-id) is ready for inference. In the dashboard’s “AI Training and Control” section, enter your model ID, and click “Start AI Control.” Phosphobot spins up a cloud GPU instance, streams camera feeds, and sends actions to your robot in real time. You can pause, resume, or tweak instructions on the fly.
- LeRobot Compatibility: Phosphobot uses the LeRobot dataset format, ensuring your data works with ACT and other models like GR00T N1 or π0. Record datasets via teleoperation, repair/merge/split them in the dashboard, and visualize them with Hugging Face’s LeRobot Dataset Visualizer.
- Hardware Simplicity: All you need is a computer to run the phosphobot server (phosphobot run) and an SO-100 arm with cameras. The cloud handles compute, so your laptop or Raspberry Pi is enough to orchestrate control.
To get started, install phosphobot on Mac, Linux or Windows with a single command:
# macos
curl -fsSL https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.sh | bash
# linux
curl -fsSL https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.sh | sudo bash
# windows
powershell -ExecutionPolicy ByPass -Command "irm https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.ps1 | iex"
Learn more about phospho and how to get started in the documentation.
Conclusion
Action Chunking with Transformers (ACT) redefines imitation learning for fine-grained robotic manipulation. By combining action chunking to reduce compounding errors, temporal ensembling for smooth execution, and a CVAE framework to handle noisy human data, ACT achieves robust performance on complex bimanual tasks with minimal demonstrations. Its transformer-based architecture leverages sequence modeling to capture the intricacies of human behavior, making it a powerful tool for advancing robotic manipulation research.