Dissecting GROOT N1: A Foundation Model for Generalist Humanoid Robots

Today, we dive into GROOT N1, an open foundation model developed by NVIDIA for generalist humanoid robots. This Vision-Language-Action (VLA) model introduces a dual-system architecture and a novel training strategy to enable robots to reason about their environments, generate fluid actions, and adapt to new tasks efficiently. Trained on a diverse mix of real-robot trajectories, human videos, and synthetic data, GROOT N1 pushes the boundaries of what humanoid robots can achieve. Let's break it down step by step, exploring its design, training, and performance.
1. Foundation Models in Robotics: A Recap
Foundation models are large-scale neural networks trained on vast, diverse datasets, designed to generalize across tasks and adapt with minimal fine-tuning. In robotics, this translates to a model capable of controlling various robot embodiments—think single-arm manipulators to dexterous humanoids—while performing a wide range of tasks. GROOT N1 embodies this vision, leveraging a VLA framework to integrate visual perception, language understanding, and action generation into a unified system.
2. GROOT N1: A Vision-Language-Action Model
GROOT N1 is engineered to process visual inputs (e.g., camera images), language instructions (e.g., "pick up the apple"), and the robot’s proprioceptive state, outputting a sequence of motor actions. Its standout feature is a dual-system architecture, drawing inspiration from human cognitive processing as outlined in Daniel Kahneman’s Thinking, Fast and Slow.
Dual-System Design
- System 2: Vision-Language Module
This is the reasoning backbone, a pre-trained Vision-Language Model (VLM) named Eagle-2, fine-tuned from SmolLM2 and SigLIP-2. Running at 10 Hz on an NVIDIA L40 GPU, it processes 224x224 resolution images and text instructions, producing tokens that encapsulate the environment and task goals. Think of it as the deliberative mind, interpreting what needs to be done. - System 1: Diffusion Transformer
The action generator, a Diffusion Transformer (DiT), operates at 120 Hz, taking the VLM’s output tokens and the robot’s state to produce smooth, real-time motor actions via flow-matching. This is the fast, intuitive system, handling the how of execution.
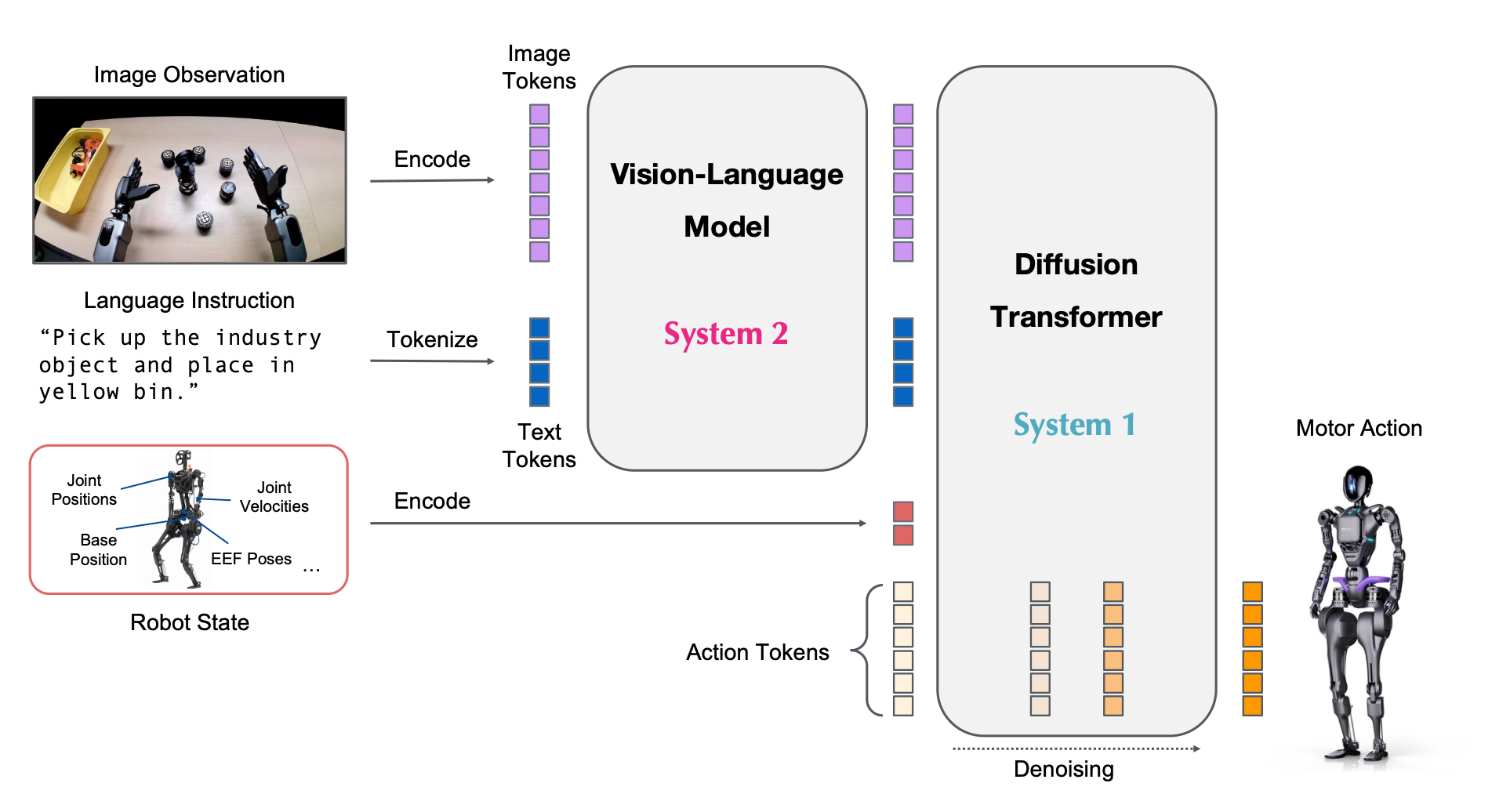
Both modules are Transformer-based, tightly coupled, and trained end-to-end. This synergy allows high-level reasoning to inform low-level action generation seamlessly, mimicking human-like coordination between thought and movement.
3. Model Architecture in Detail
System 2: Vision-Language Module
The Eagle-2 VLM encodes visual and language inputs into a shared representation. Images are processed into 64 token embeddings per frame, while text instructions are tokenized in a chat-like format. These embeddings, extracted from the 12th layer of the VLM, feed into System 1, balancing inference speed and task performance.
System 1: Diffusion Transformer
The DiT generates actions by denoising noised action samples, conditioned on VLM tokens and robot state. It uses:
- Embodiment-specific MLPs: To project variable state and action spaces into a shared embedding dimension, enabling cross-embodiment compatibility.
- Flow-matching: An iterative denoising process where action chunks (16 timesteps) are predicted, ensuring smooth, closed-loop control.
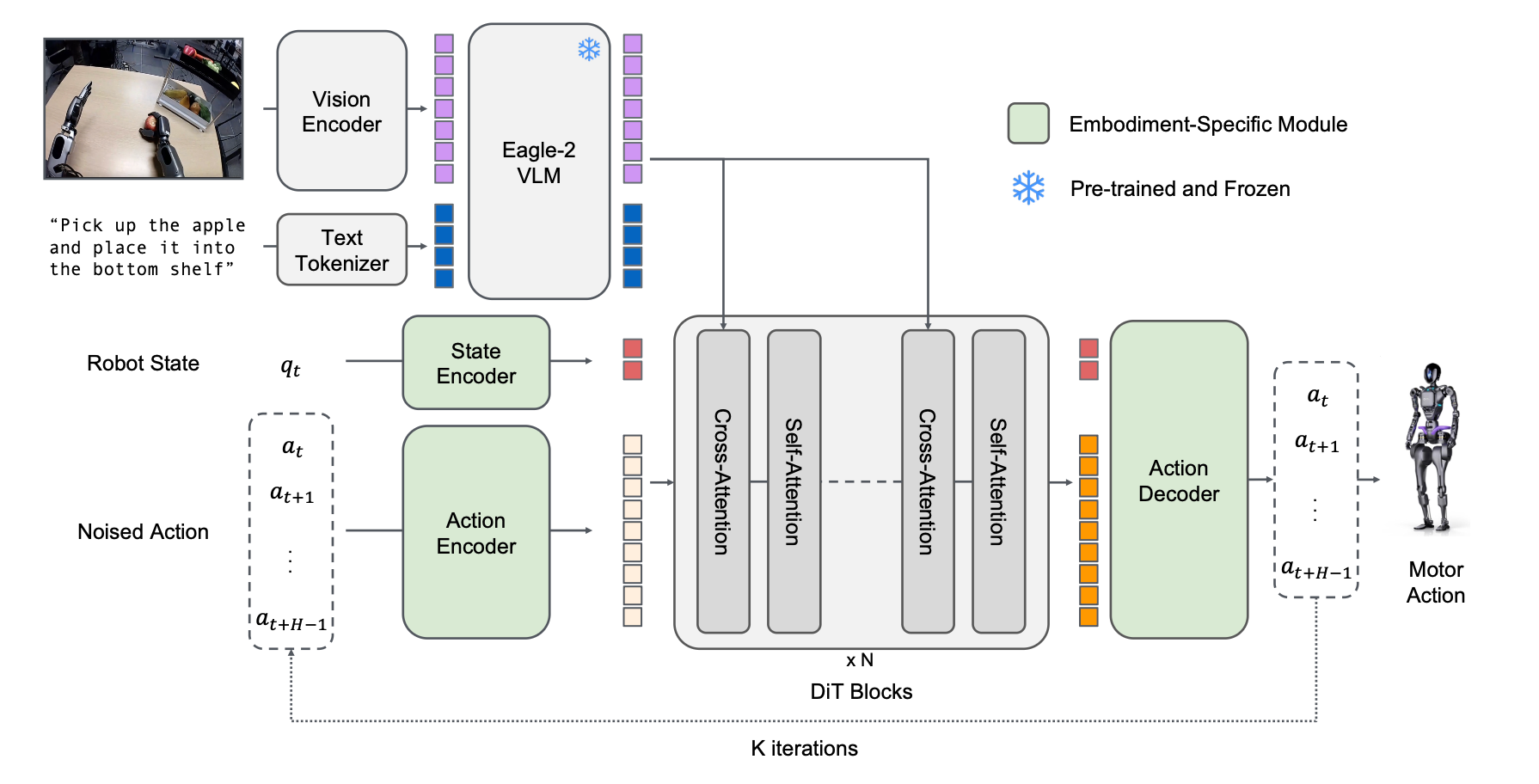
This design supports diverse embodiments—from single-arm robots to bimanual humanoids—making GROOT N1 a true generalist.
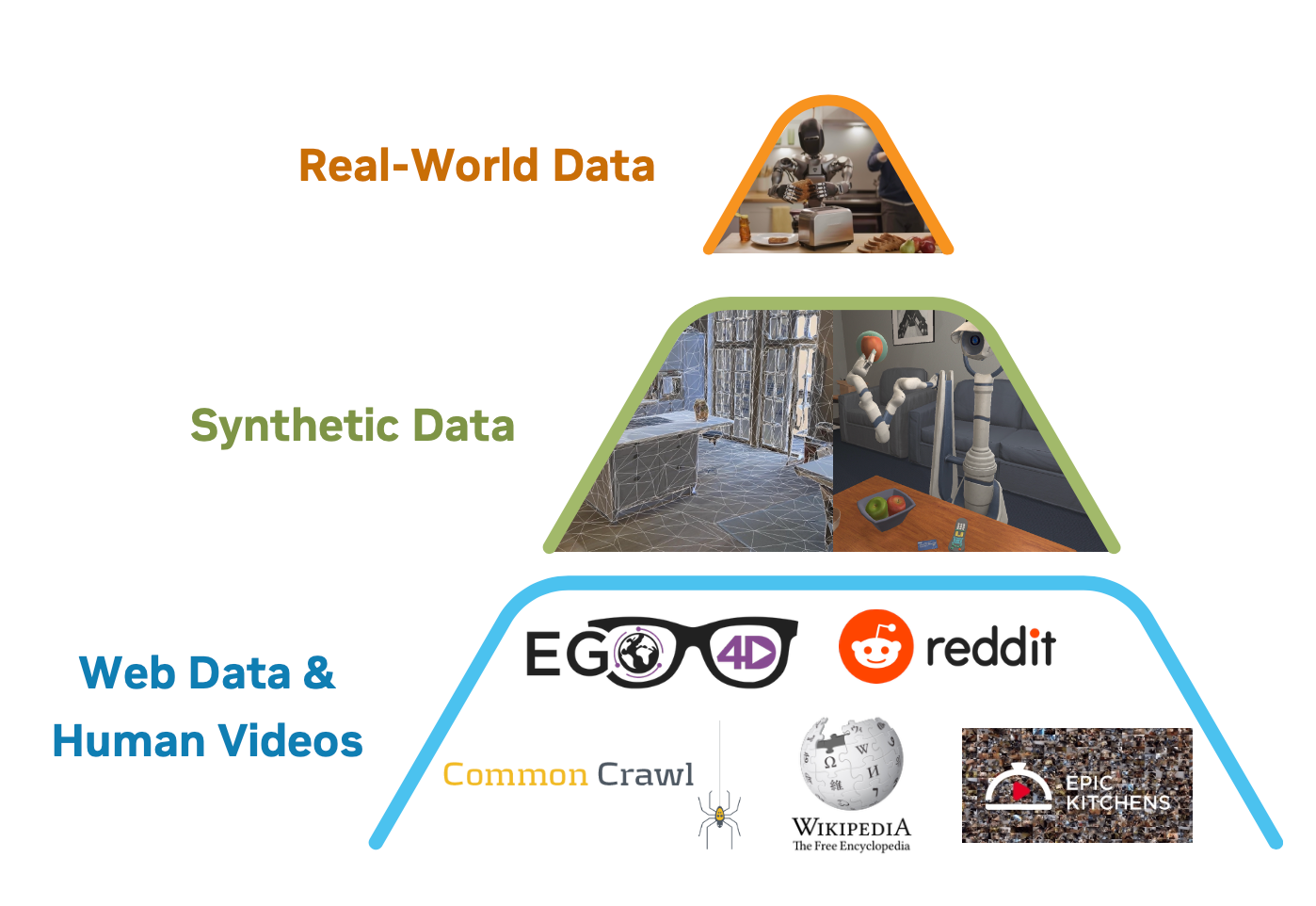
4. Training Data: The Data Pyramid
Training a robotics foundation model demands massive, varied data, but real-robot trajectories are scarce. GROOT N1 addresses this with a data pyramid:
- Base: Web data and human videos (e.g., Ego4D, EPIC-KITCHENS), providing broad behavioral priors.
- Middle: Synthetic data from simulations (e.g., DexMimicGen) and neural-generated videos, bridging general knowledge to embodied tasks.
- Top: Real-robot trajectories (e.g., GR-1 teleoperation data), grounding the model in physical execution.
Handling Action-Less Data
Human videos lack explicit actions, so the team employs:
- Latent-action Codebook: A VQ-VAE extracts latent actions from video frame pairs, trained across all data for a unified action space.
- Inverse Dynamics Model (IDM): Predicts pseudo-actions from consecutive frames, augmenting action-less data.
This unification creates a consistent dataset of states, observations, instructions, and actions, enabling end-to-end training.
5. Training Strategy
Pre-Training
GROOT N1 is pre-trained on the full data pyramid, sampling from real, synthetic, and human datasets. The flow-matching loss optimizes action generation, with latent or pseudo-actions used for non-robot data. This phase builds general capabilities across embodiments.
Post-Training
Fine-tuning adapts the model to specific tasks or robots, leveraging its pre-trained knowledge for data-efficient learning. Neural trajectories further augment this phase, scaling task-specific data with generated videos.
6. Evaluation and Results
Simulation Benchmarks
GROOT N1 was tested on three benchmarks:
- RoboCasa Kitchen: 24 tasks with a Franka Panda arm, outperforming baselines like Diffusion Policy in success rates (e.g., 49.6% vs. 43.2% with 300 demos).
- DexMimicGen Suite: 9 bimanual tasks across three embodiments, achieving 74.2% average success vs. 68.4% for Diffusion Policy.
GR-1 Tabletop: 24 humanoid tasks, showing competitive performance (49.3% average).
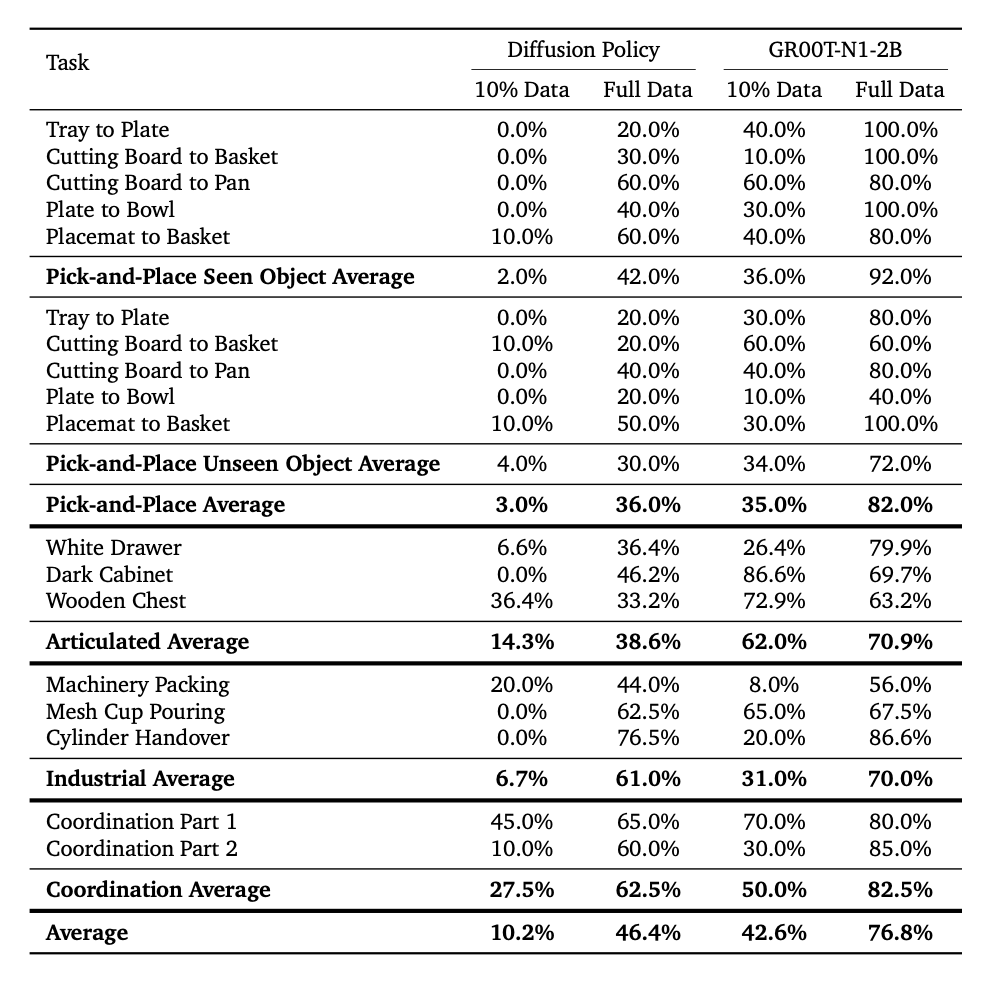
Real-World Performance

Deployed on the Fourier GR-1, GROOT N1 excels in tasks like pick-and-place (82% average success with full data) and articulated object manipulation (70.9%), demonstrating high data efficiency even with 10% data (42.6% average).
7. Test GROOT N1 on your own robot
GR00T N1 is a beast of a model, and running it locally is no small feat. Let’s do some napkin math to understand why, and then explore what are alternatives.
Running GROOT N1 Locally: A Heavy Lift
GR00T N1’s 2.2 billion parameters (1.34B in the VLM alone) demand serious hardware. The paper reports inference times of 63.9 ms for a chunk of 16 actions on an NVIDIA L40 GPU using bfloat16 precision. Let’s break it down:
- Memory Footprint: A 2.2B parameter model in bfloat16 (2 bytes per parameter) requires roughly 4.4 GB for weights alone. Add activations, intermediate buffers, and vision processing (224x224 images), and you’re looking at ~10-12 GB of GPU memory for inference. For fine-tuning, double that to account for gradients and optimizer states—call it ~20-24 GB.
- Compute Power: The L40 GPU, with 48 GB VRAM and ~90 TFLOPS (FP16), handles the dual-system architecture (VLM at 10 Hz, DiT at 120 Hz). A consumer-grade RTX 3090 (24 GB, ~35 TFLOPS) might squeak by for inference with aggressive optimizations, but fine-tuning or real-time control on a humanoid like the GR-1 would be sluggish or infeasible. Pre-training? Forget it—50,000 H100 GPU hours (~1024 GPUs for days) is enterprise-level compute.
For hobbyists or small labs, this is a tall order. Even if you have the hardware, setting up the environment, managing dependencies, and optimizing for real-time control is a slog.
Using phospho: Fine-Tuning and Inference Made Simple
Instead of wrestling with local compute, phosphobot offers a streamlined solution using its cloud GPU infrastructure. Built for ML engineers, phosphobot integrates with the SO-100 robot arm (and others) and supports GR00T N1 out of the box. Here’s why it’s the best way to try GR00T N1:
- One-Click Fine-Tuning: From the phosphobot dashboard, you can fine-tune GR00T-N1-2B on your own dataset (e.g., recorded via teleoperation with the Meta Quest app). Just upload your LeRobot v2.1 dataset to Hugging Face, enter its ID (e.g., phospho-app/my-dataset), and hit “Train AI Model.” Phosphobot’s cloud handles the heavy lifting—think A100 or H100 GPUs—taking ~3 hours for ~50 episodes. No need to wrangle local GPUs or debug CUDA errors.
- Seamless Inference: Once trained, your model (e.g., phospho-app/my-dataset-random-id) is ready for inference. In the dashboard’s “AI Training and Control” section, enter your model ID, specify a task instruction (e.g., “pick up the green lego brick”), and click “Start AI Control.” Phosphobot spins up a cloud GPU instance, streams camera feeds, and sends actions to your robot in real time. You can pause, resume, or tweak instructions on the fly.
- LeRobot Compatibility: Phosphobot uses the LeRobot dataset format, ensuring your data works with GR00T N1 and other models like ACT or π0. Record datasets via teleoperation, repair/merge/split them in the dashboard, and visualize them with Hugging Face’s LeRobot Dataset Visualizer.
- Hardware Simplicity: All you need is a computer to run the phosphobot server (phosphobot run) and an SO-100 arm with cameras. The cloud handles compute, so your laptop or Raspberry Pi is enough to orchestrate control.
To get started, install phosphobot on Mac, Linux or Windows with a single command:
# macos
curl -fsSL https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.sh | bash
# linux
curl -fsSL https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.sh | sudo bash
# windows
powershell -ExecutionPolicy ByPass -Command "irm https://raw.githubusercontent.com/phospho-app/phosphobot/main/install.ps1 | iex"
Learn more about phospho and how to get started in the documentation.
8. Conclusion
GROOT N1 advances generalist robot autonomy with its dual-system VLA architecture and data pyramid strategy. Its ability to learn from human videos and synthetic data hints at a future where robots leverage internet-scale resources for skill acquisition. The open release of the GROOT-N1-2B checkpoint, datasets, and benchmarks invites further exploration, accelerating progress toward versatile, intelligent humanoids.
Learn more in the original paper here.