llama 2 vs gpt 4: When to choose which?
Exciting news, phospho is now bringing brains to robots!
With phosphobot, you can control robots, collect data, fine-tune robotics AI models, and deploy them in real-time.
Check it out here: robots.phospho.ai.
A large language model (LLM) is essentially a form of AI that is specifically designed to understand and generate natural human language. They can process huge amounts of data so they are often deployed as context informed chat bots, content and code creation tools, and multi-lingual translators.
As novel and booming as they are right now, they require a lot of training from vast data sets. The GPT-3 model, a predecessor to GPT-4, was trained on 570GB of text data, showcasing the scale of these models.
Comprehensive comparisons are usually drawn from benchmark tests to best inform your decision making when choosing between LLMs.
So your choice should incorporate these metrics to really understand which LLMs are better for different use cases given their respective customisability and adaptability to specific tasks.
This is why your choice of LLM is important to get right early on as it translates into the scope of flexibility and performance for your LLM app going forwards.
In this article we’ll explore the differences between LLama 2 and GPT-4 and also go over specific use cases best suited to each LLM.
Quick Comparison: Benchmarks used in LLM evaluation
Much like our previous articles comparing GPT-4 to other LLMs such as Gemini here or Claude 3 here, we always refer to the benchmark evaluations to provide a comprehensive comparison between different LLMs.
So let’s first have a look at how they compare in a few key benchmark metrics:
- Llama-2-70B scored 81.7% accuracy at spotting factual inconsistencies in summarised news snippets. This nearly matches GPT-4's 85.5% accuracy.
- Llama-2-70B and GPT-4 achieved near human-level performance of 84% accuracy on fact checking tasks.
So Llama 2 demonstrates factual accuracy on par with GPT-4 when summarising text. This validates the potential of Llama 2 for high integrity summarisation applications.
- Llama 2 approached GPT-4's high scores of 80-100% on exams like the LSAT and SAT, scoring 71.2% on the code focused Codex HumanEval test.
- While GPT-4 improved substantially in areas like biology exams, Llama 2 made parallel strides in general knowledge by utilising 40% more training data.
- For image classification on ImageNet, Llama 2 matched GPT-4's state of the art 89.6% accuracy
- In benchmarks of mathematical reasoning, GPT-4 significantly outperforms Llama-2, with superior analytical abilities.
- GPT-4 achieves a higher overall evaluation score across NLP (natural language) datasets due to its larger scale.
- With expanded context lengths and multilingual support, GPT-4 remains better suited for longer, more complex textual inputs.
So while GPT-4 maintains strengths in some specialised domains, Llama 2 proves highly capable across a wide range of language and reasoning benchmarks, even exceeding GPT-4 in select contexts. As an open-source project, Llama 2 has ample room to continue advancing beyond current proprietary LLMs.
However, smaller 7B and 13B Llama 2 models failed to follow instructions and exhibited extreme ordering bias. Their fact-checking accuracy remained far below random chance.
Bigger models like GPT-4 and Llama-2-70B were much better at avoiding these biases. So smaller Llamas may not be suitable for summarisation tasks requiring rigorous factual diligence.
How to quickly test each LLM yourself
The best evaluation you can provide is one with real world application with your own product, there’s no better way to see if an LLM performs better than the other.
To test the viability and performance of each model yourself, try integrating them both into your LLM app and use text analytics tools like Phospho to get full visibility into which one performs better for you with a data driven approach.
With Phospho you can monitor user interactions for AI products in real-time with our text analytics platform. The real leverage comes from setting your own automated custom KPIs that flag user interactions when detected so you can get far more visibility into what’s working and what’s not.
However, as this article is a comparison between Llama 2 and GPT-4, for more detail about what Phospho offers LLM apps, read our previous article here about how much insights you can get from leveraging AI analytics tools like Phospho to draw better LLM conclusions with data.
Llama 2 Overview
Llama 2, the LLM built by Meta took a bold stance in open sourcing its model which is quite novel in the gen AI space.
Llama 2 is available in three sizes — 7B, 13B, and 70B parameters, as well as in pre-trained and fine-tuned variations. Meta also trained a 34B parameter version, but it was never released.
As showcased in the comparison above, Llama 2 is very good at leveraging its larger training data for general knowledge and providing accurate summarisations from text.
Best practical use cases:
****Llama 2 is best suited for lean, tight budgeted teams looking for cost effective LLM solutions. In terms of practical use cases, Llama 2’s open source nature, efficiency, and low cost make it a sensible choice for summarisation apps and internal resource apps that don’t require the complexity or creativity you’d need GPT-4 for.
Summarisation at scale:
It’s cost per paragraph summary is ~30x less than GPT-4 while maintaining the same accuracy. So for startups and small teams requiring high quality summarisation at scale, Llama 2 offers cost effective deployments while maintaining similar performances to that of GPT-4.
Internal resources:
Llama 2 is more efficient and considered faster than GPT-4 which makes it the ideal LLM for apps companies or academic institutions need for internal reasons such as document, research, e-learning resources, and onboarding material for staff and employees. This is because you would get the benefits of computational agility and efficiency in gathering necessary material quickly whilst also prioritising better data privacy and security of employee/company data and sensitive research material compared to that of closed models like GPT-4.
It’s open source nature also provides flexibility and transparency for integrating and customising your AI models without taking on high costs.
Under these use cases Llama 2 can be a better LLM choice over GPT-4 for more budget conscious startups and companies who don’t need to prioritise absolutely top tier reasoning but might need more data security that comes with opting for an open source solution.
GPT-4 Overview
As you’re probably likely aware, GPT-4 is an LLM developed by OpenAI. Unlike LLama 2, the inner workings of GPT-4 are not open source so are unknown. It’s also only available to users with a paid subscription to Chat GPT.
GPT-4 has outstanding multimodal capabilities when processing different inputs such as text, images, and video making it a clear favourite LLM for use cases that prioritise visual understanding.
It also excels at generating complex code and given its many third party plugins, offers developers a no brainer choice of LLM when requiring flexibility and ease of integration to customise AI apps to their liking.
This is obviously on top of the high quality text generation you would expect from the leading LLM on the market making it very suitable for conversational AI and content creation.
Best practical use cases:
GPT-4 is the better option for more advanced use cases and startups or teams looking for the most flexibility in capabilities. It’s far better at understanding natural language and nuance which positions it strongly for apps requiring creativity, reasoning and problem solving that would come with high quality content creation or complex coding and analytics.
Content creation:
GPT-4 excels at creative writing. In fact, when producing poetry in benchmark tests, GPT-4 produced far more advanced vocabulary and expressions which reflects its higher capacity for complexity. For more in demand text generation and multimodal understanding such as content creation it’s able to produce higher quality copy with its advanced language capabilities for social media and marketing materials.
Complex coding and analytics:
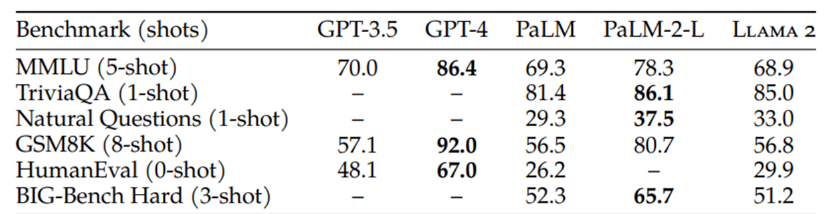
Developers are already familiar with GPT-4’s capabilities and how it’s best suited for customising AI models to best suit their needs, especially when you consider the array of third-party plugins available for quickly adding further functionality and capability to your app. For coding benchmarks like HumanEval, GPT-4 more than doubles Llama 2's accuracy at 67% vs 29.9%.
So while Llama 2 competes on overall accuracy, GPT-4's scale and broader effectiveness is better suited for industries demanding versatility. For more diverse use cases that require creativity and problem solving, GPT-4 is still the most capable option between the models.
Choosing between Llama 2 and GPT-4
Both LLMs have good reasons to choose one over with their respective strengths in different scenarios, but choosing the best model for you depends on what you plan to use it for and what requirements come along with that use case.
The key things to consider when trying to make this decision for yourself are your availability of resources, your specific use case, and ease of integration and compatibility with any existing systems.
Want to take AI to the next level?
At Phospho, we give brains to robots. We let you power any robot with advanced AI – control, collect data, fine-tune, and deploy seamlessly.
New to robotics? Start with our dev kit.
👉 Explore at robots.phospho.ai.