LLM Colosseum

Exciting news, phospho is now bringing brains to robots!
With phosphobot, you can control robots, collect data, fine-tune robotics AI models, and deploy them in real-time.
Check it out here: robots.phospho.ai.
A Mistral Hackathon project
In this blog post, we wanted to take a moment to present an old project of ours, LLM Colosseum.
The idea was to make LLMs fight in an arena to determine which was the best one. Gladiator style.
We got the idea while participating in a Hackathon in SF, here’s what it looks like:
LLM colosseum - a Mistral hackathon project
You can check the code on GitHub here: https://github.com/OpenGenerativeAI/llm-colosseum
The Idea of Using LLMs for Reinforcement Learning
Traditionally, for tasks like training an agent to perform in an arena, we would use reinforcement learning.
Such algorithms have relied on neural networks to learn policies based on reward signals and environmental feedback.
However, LLMs bring a unique perspective to this domain by leveraging their natural language understanding capabilities.
By converting game states into textual descriptions and prompting the LLMs with these descriptions, we open up new avenues for exploration and decision-making.
LLMs have the potential to excel in reinforcement learning tasks due to their ability to grasp complex contexts and reason about abstract concepts.
Unlike traditional reinforcement learning agents that operate solely on numerical inputs, LLMs can comprehend the nuances of natural language descriptions, enabling them to make more informed and strategic decisions.
This approach allows for the incorporation of high-level reasoning, strategic planning, and even creative problem-solving, which could lead to more sophisticated and adaptable agents.
Measuring Speed, Quality of Prediction, and Resilience
In the LLM Colosseum project, three key metrics are used to evaluate the performance of LLMs in the Street Fighter III game environment: speed, quality of prediction, and resilience.
Speed
Speed is a crucial factor in real-time games like Street Fighter, where split-second decisions can make or break a match.
Winning LLMs must demonstrate the ability to process game states rapidly and generate effective moves with minimal latency, ensuring a smooth and responsive gameplay experience.
Quality
Quality of prediction refers to the ability of LLMs to anticipate and outsmart their opponents.
By analyzing the current game state, the LLM must think several steps ahead, considering potential moves from both players and formulating strategies that maximize their chances of success.
This requires not only a deep understanding of the game mechanics but also the capability to reason abstractly and make intelligent decisions based on complex patterns and contexts.
Resilience
Resilience is another critical aspect evaluated in the LLM Colosseum.
In a fast-paced fighting game, the ability to adapt and recover from setbacks is essential.
LLMs must demonstrate the capacity to learn from mistakes, adjust their strategies on the fly, and maintain a high level of performance throughout the entirety of a match.
This trait highlights the robustness and adaptability of LLMs, showcasing their potential to handle dynamic and challenging environments.
LLM colosseum - a Mistral Hackathon project
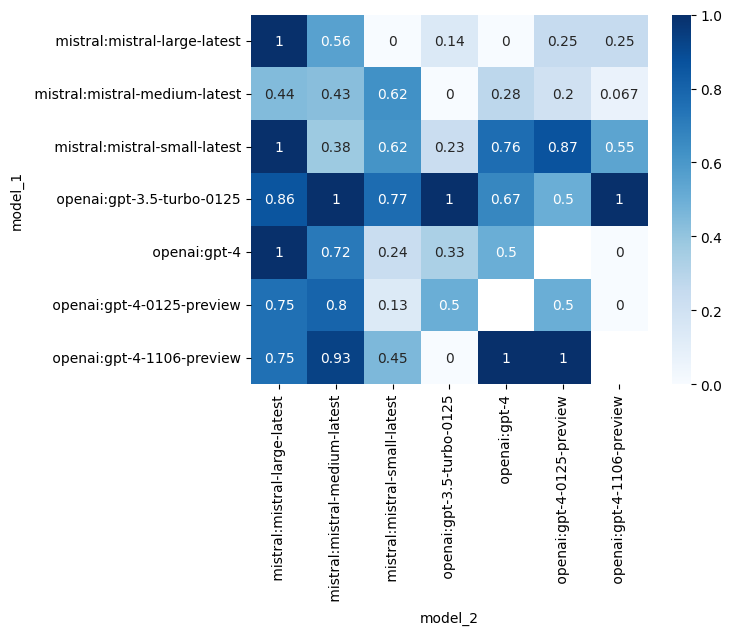
Insights into the results
After conducting an extensive series of 342 fights, we’ve assigned an ELO score to each model.
The leaderboard is a testament to the remarkable abilities of these language models, with OpenAI's gpt-3.5-turbo-0125 emerging as the undisputed champion with an impressive ELO rating of 1776.11.
Mistral-small however shows great potential in its ability to make quick decisions, scoring second place in the ranking.
This diversity highlights the versatility of LLMs and their potential to excel in various domains, given the right training and optimization strategies.
As the LLM Colosseum project continues to evolve, it promises to provide invaluable insights into the capabilities of these models, ultimately paving the way for more advanced and intelligent AI systems.
Want to take AI to the next level?
At Phospho, we give brains to robots. We let you power any robot with advanced AI – control, collect data, fine-tune, and deploy seamlessly.
New to robotics? Start with our dev kit.
👉 Explore at robots.phospho.ai.
Thanks for reading, we'll see you in the next one!