Understanding pi0 by Physical Intelligence: A Vision-Language-Action Flow Model for General Robot Control
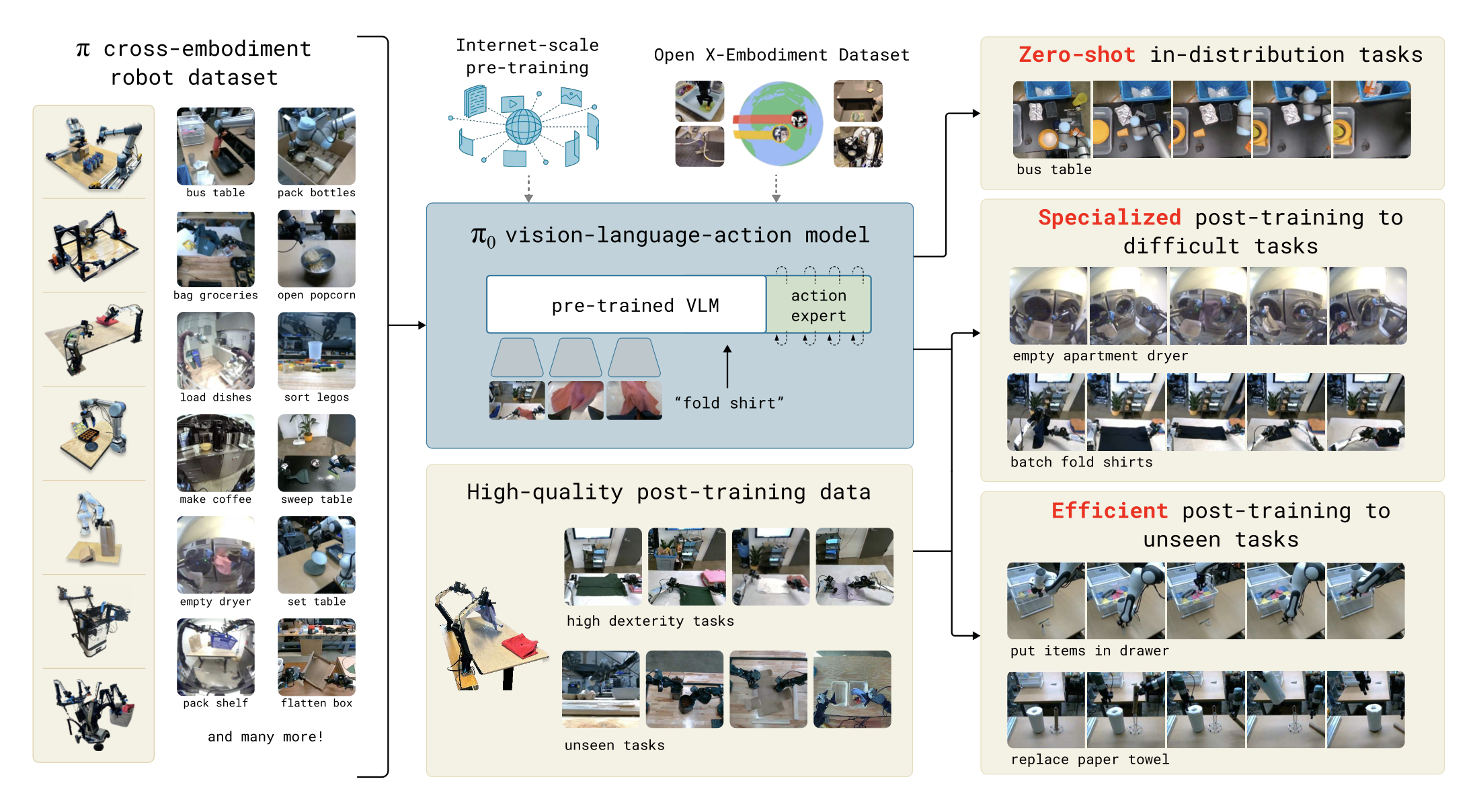
In this blog post, we explore the π₀ model, a Vision-Language-Action (VLA) flow model developed by Physical Intelligence for general robot control. This post dissects the research paper, focusing on its architecture, training methodology, and experimental results.
Model Overview
The πzero model is designed as a foundation model for robotics, aiming to generalize across diverse tasks and robot embodiments. It builds upon a pre-trained vision-language model (VLM), specifically PaliGemma with 3 billion parameters, and extends it with an action generation mechanism using flow matching. This hybrid approach integrates internet-scale semantic understanding with precise, continuous action outputs, enabling dexterous manipulation.
The model's strengths lie in four core innovations:
- Vision-Language-Action (VLA) Architecture: Leveraging a pre-trained VLM, pi₀ taps into a vast reservoir of semantic knowledge from internet-scale data, adapting it for robotic control.
- Flow Matching for Action Generation: By employing flow matching—a diffusion-inspired technique—pi₀ generates continuous, high-frequency actions essential for dexterous tasks.
- Cross-Embodiment Training: Training on data from multiple robot platforms enables pi₀ to adapt to varying kinematic configurations.
- Two-Phase Training Recipe: A pre-training phase on diverse data followed by fine-tuning on task-specific, high-quality data mirrors strategies used in large language models, balancing generality with precision.
Architecture Breakdown
The πzero model is a transformer-based system that integrates vision, language, and action into a cohesive framework. Here’s how it’s structured.
1. Vision-Language Model (VLM) Backbone
At its core, π₀ uses PaliGemma, a 3 billion parameter VLM pre-trained on internet-scale image-text pairs. This backbone encodes images into embeddings that align with language tokens, providing a rich understanding of visual scenes and instructions.
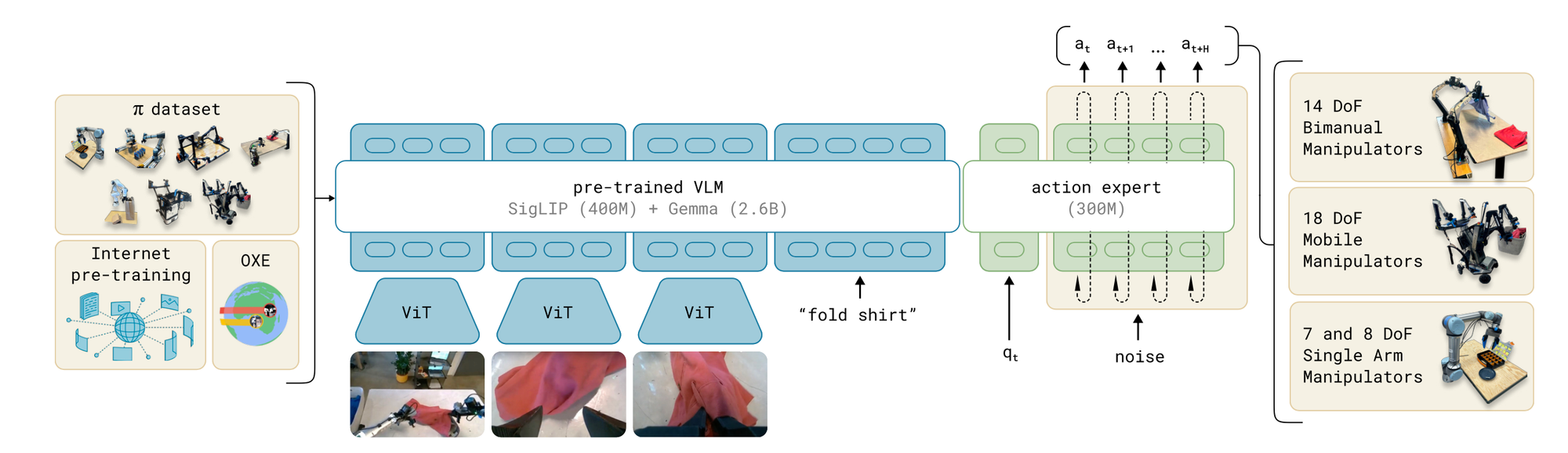
For robotics, this pre-trained knowledge is extended to handle robot-specific inputs and outputs, which brings us to the next layer of the design.
2. Incorporating Robot States and Actions
To bridge the gap from vision-language understanding to physical control, pi₀ incorporates:
- Proprioceptive State: Represented as a vector of joint angles (q_t), this input captures the robot’s current configuration. It’s encoded and projected into the same embedding space as image and language tokens.
- Action Chunks: Rather than predicting a single action, pi₀ generates a sequence of future actions (A_t = [a_t, a_t+1, ..., a_t+H-1], where H=50). This chunking approach ensures smooth, continuous control, critical for tasks like folding laundry.
These elements are processed alongside visual and linguistic inputs, but the real magic happens in how actions are generated.
3. Flow Matching for Action Generation
Traditional action prediction might discretize outputs, but pi0 opts for flow matching, a method inspired by diffusion models, to model continuous action distributions. Here’s the process:
- Training: Given an observation o_t, the model learns to denoise an action chunk A_t from a noisy version A_t^tau, where tau (ranging from 0 to 1) controls the noise level. The training objective is to minimize the difference between the model’s predicted vector field v_theta(A_t^tau, o_t) and the true denoising vector u(A_t^tau | A_t). The loss function is:
L^tau(theta) = E[p(A_t | o_t), q(A_t^tau | A_t)] [ || v_theta(A_t^tau, o_t) - u(A_t^tau | A_t) ||^2 ]
Here, q(A_t^tau | A_t) follows a linear-Gaussian path: A_t^tau = tau * A_t + (1 - tau) * epsilon, with epsilon drawn from a standard normal distribution.
- Inference: Starting from pure noise (A_t^0 ~ N(0, I)), the model iteratively refines the action chunk using Euler integration:
A_t^(tau + delta) = A_t^tau + delta * v_theta(A_t^tau, o_t)
With 10 steps (delta = 0.1), this produces a clean action sequence at up to 50 Hz—ideal for dexterous manipulation.
This flow matching approach allows πzero to capture multimodal action distributions, enhancing its precision and adaptability.
4. Action Expert
To efficiently process robotics-specific data, π₀ employs an “action expert”—a separate set of transformer weights (adding 300 million parameters) dedicated to proprioceptive states and action tokens. Unlike the VLM backbone, which handles images and language, the action expert uses full bidirectional attention across action tokens, ensuring coherent sequence generation.
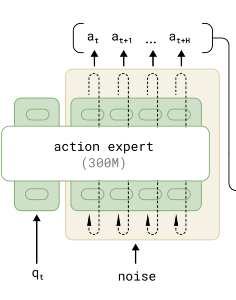
This mixture-of-experts-inspired design lets π₀ leverage pre-trained knowledge while specializing in robotic control, culminating in a total of 3.3 billion parameters.
Training Methodology
The training of pi₀ follows a two-phase strategy: pre-training and post-training, mirroring large-scale language model recipes.
Pre-training Phase
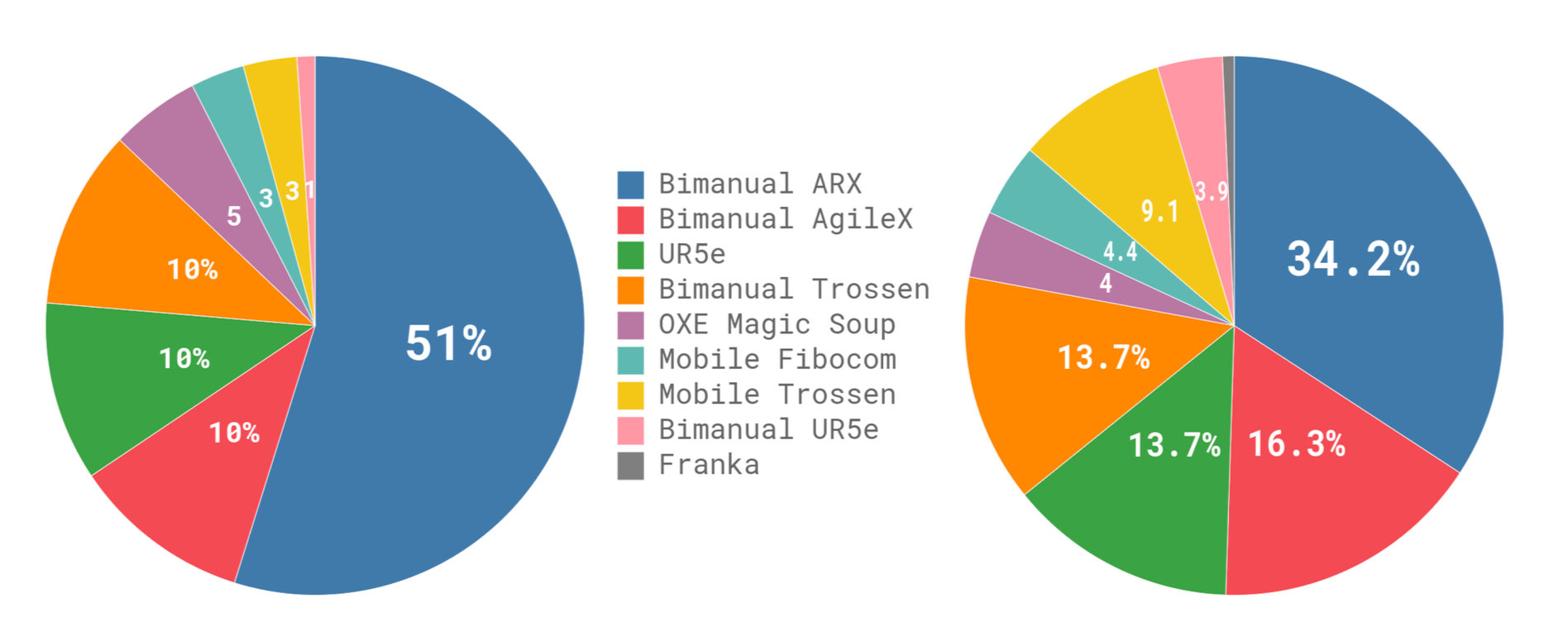
Pre-training leverages a massive dataset of over 10,000 hours from seven robot configurations (e.g., UR5e, Bimanual Trossen, Mobile Fibocom) and 68 tasks, augmented with open-source datasets like OXE and DROID. This cross-embodiment dataset, totaling 903 million timesteps from in-house data plus 9.1% open-source contributions, ensures broad generalization. Tasks range from simple object relocation to complex laundry folding, with language labels (task names and segment annotations) enhancing semantic grounding.
Data imbalance is addressed by weighting each task-robot combination by ( n^{0.43} ), where ( n ) is the sample count, down-weighting overrepresented subsets. Action and state vectors are zero-padded to a uniform 18-dimensional space to accommodate diverse robot kinematics.
Post-training Phase
Post-training fine-tunes π₀ on task-specific datasets, ranging from 5 to over 100 hours, to achieve high proficiency. This phase emphasizes efficient, robust execution, leveraging high-quality curated data. Pre-training provides mistake recovery and generalization, while post-training instills optimal strategies, a synergy validated by empirical results.
Language Integration and Hierarchical Control
The VLM backbone enables π₀ to interpret natural language commands (e.g., "fold the laundry"), translating them into action sequences via the action expert. For complex tasks, a high-level policy decomposes objectives into subtasks (e.g., "pick up the napkin"), executable as intermediate language commands. This hierarchical structure, inspired by systems like SayCan, enhances performance on temporally extended tasks.
Experimental Results
The evaluation spans four axes: out-of-box performance, language following, adaptation to new tasks, and complex multi-stage tasks.
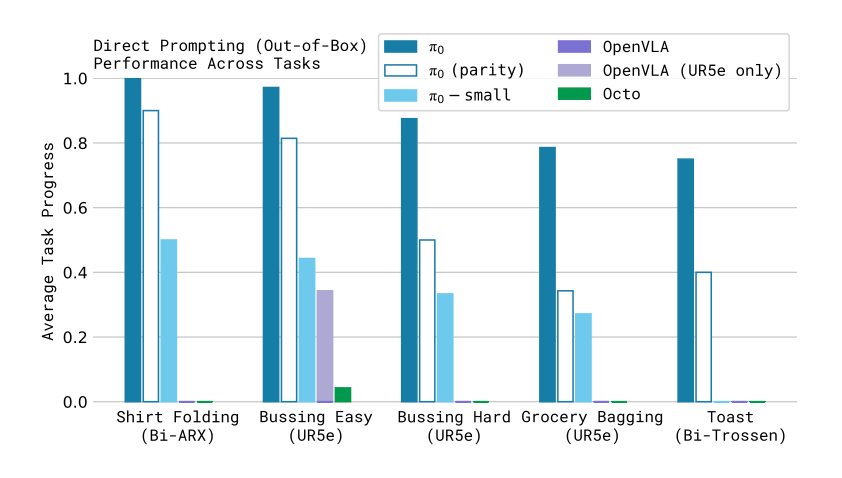
Out-of-Box Performance
Post-pre-training, π₀ is tested on five tasks: shirt folding, bussing (easy and hard), grocery bagging, and toast removal. Compared to baselines like OpenVLA and Octo, π₀ excels, achieving near-perfect scores on simpler tasks and significant gains on complex ones, even at compute parity (160k vs. 700k training steps).
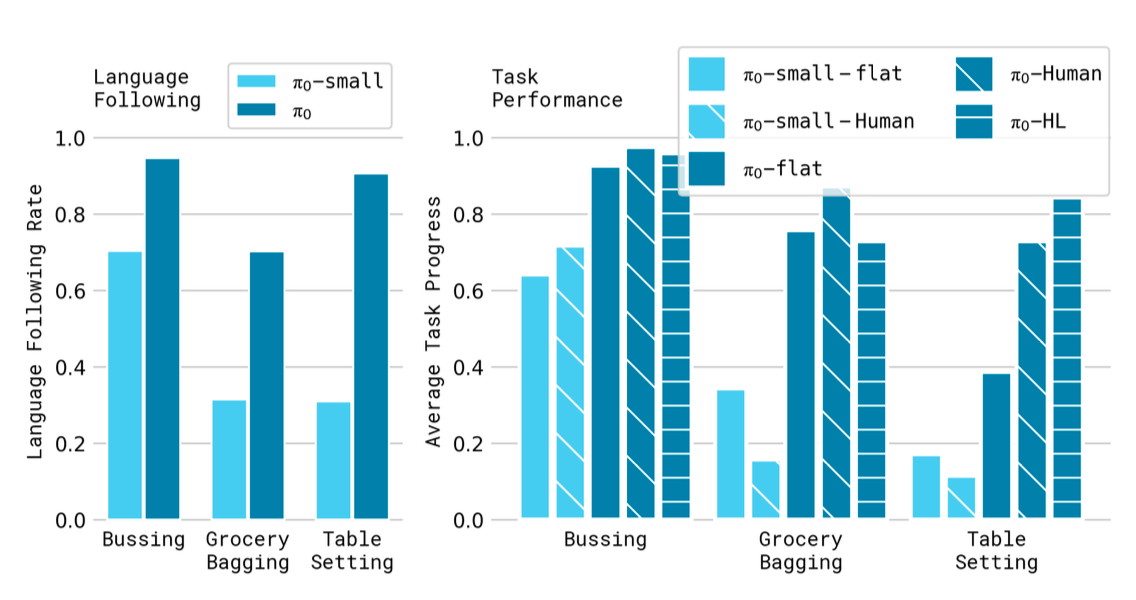
Language Following
Fine-tuned π₀ outperforms a non-VLM baseline (π₀-small) on tasks like bussing and table setting, leveraging VLM pre-training for superior language comprehension. Human-provided intermediate commands boost performance further, with autonomous high-level VLM guidance showing promise.
Adaptation to New Tasks
Fine-tuning on unseen tasks (e.g., stacking bowls, paper towel replacement) demonstrates π₀'s adaptability. It surpasses methods like ACT and Diffusion Policy, with pre-training amplifying gains on tasks closer to the pre-training distribution, validated across varying dataset sizes (1 to 25 hours).
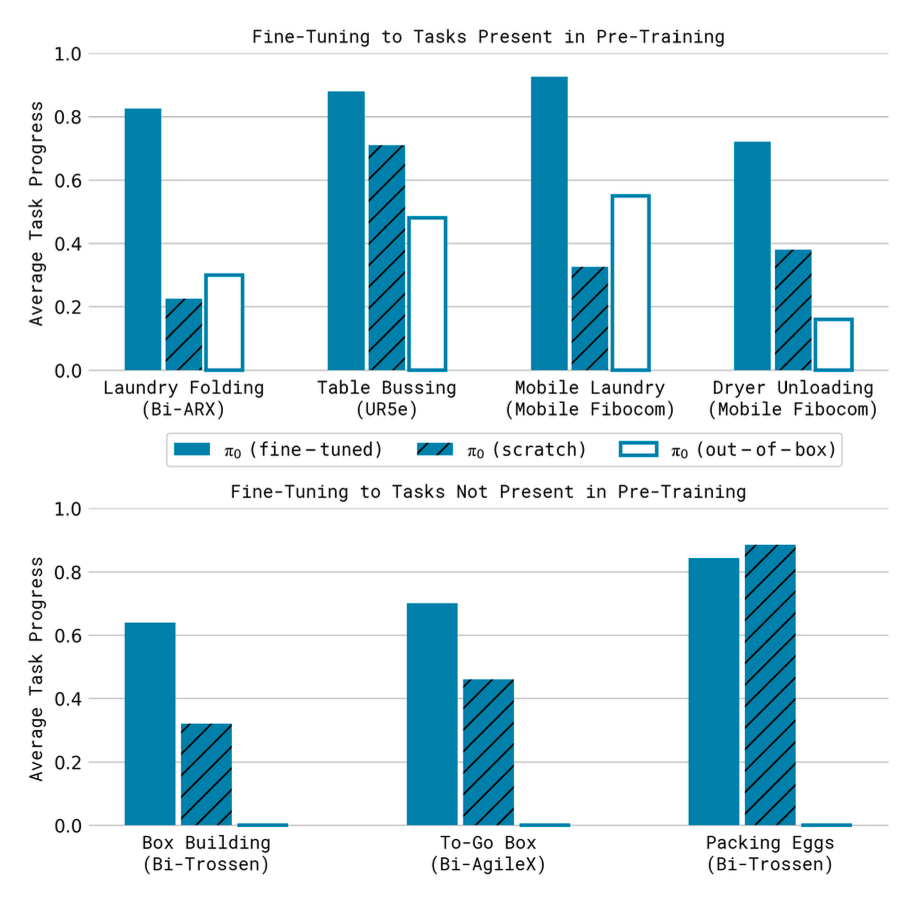
Complex Multi-Stage Tasks
π₀ tackles tasks like laundry folding and box assembly, some absent from pre-training. Scores exceed 50% of maximum, with pre-training and fine-tuning outperforming ablations (scratch training or out-of-box use). Tasks like table bussing with novel objects highlight its generalization and dexterity.
Technical Insights
- Flow Matching vs. Diffusion: Flow matching’s efficiency in modeling continuous actions at high frequency (50 Hz) distinguishes π₀ from autoregressive VLAs, enhancing dexterity.
- Pre-training Scale: The 10,000-hour dataset, unprecedented in scope, underpins π₀’s generalization, akin to internet-scale text corpora for LLMs.
- Action Expert Design: Separating action generation weights optimizes performance, resembling a mixture-of-experts approach within a single transformer.
Testing π₀ on your own robot
While π₀ demonstrates impressive capabilities, deploying it locally presents significant challenges:
- Computational Demand: With 3.3 billion parameters, π₀ requires substantial resources, typically high-end GPUs, for efficient training and inference.
- Real-Time Performance: Achieving the 50 Hz action generation needed for dexterous tasks is difficult on local hardware, especially for complex manipulations.
- Complex Setup: Configuring the environment involves managing specific library versions, dependencies, and hardware compatibility, which can be time-consuming and error-prone.
- Data Stream Management: Processing real-time camera feeds and generating actions without latency demands a robust local setup.
One of the solution is to use a tool like phospho to:
- connect to your local robot
- easily record a dataset
- use the one-click fine-tuning of a VLA on phospho cloud GPUs
- perform real-time inference from a remote phospho cloud GPU
phospho is LeRobot compatible and can be used with various low-cost robotics embodiments such as the SO-100.
Learn more about phospho and how to get started in the documentation.
Conclusion
The π₀ model advances robot control by marrying VLM pre-training with flow matching, supported by a robust pre-training and fine-tuning recipe. Its ability to generalize across tasks and robots, interpret language, and master complex manipulations marks a milestone in robotic foundation models. Future work may refine dataset composition and extend universality to domains like legged locomotion, building on this strong foundation.