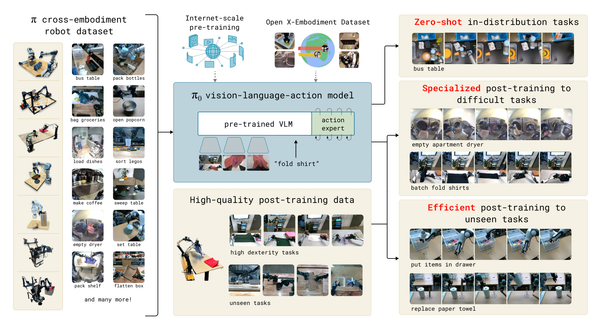
Fine-grained robotic manipulation tasks, such as threading a zip tie or opening a translucent condiment cup, demand high precision, delicate coordination, and robust visual feedback. These tasks challenge traditional imitation learning due to compounding errors, non-Markovian human behavior, and noisy demonstration data. Action Chunking with Transformers (ACT) is